1. Intel Xe GPU 架构
2. General-Purpose Computing on GPU
2.1. Execution Model Overview
2.2. Thread Mapping and GPU Occupancy
2.3. Kernels
在 oneAPI 卸载模型中,kernel 是执行计算的单元。你可以在一个迭代空间上提交一个 kernel,这样就可以对指定的数据对象进行计算。
本节将介绍与 kernel 编程、提交和执行相关的内容。
2.3.1. Sub-Groups and SIMD Vectorzation
ND-Range kernel 的索引空间被划分为 work-group,sub-group 和 work-item 。work-item 是最基本的单位。一组 work-item 组成一个 sub-group,一组 sub-group 组成一个 work-group。work-item 和 work-group 到硬件向量引擎 (VE) 的映射是依赖于实现的。所有的 work-group 都同时运行,但根据资源的可用性,它们可能被安排在不同的时间运行。work-group 的执行可能会或者不会被抢占,这取决于底层硬件的能力。同一 work-group 中的 work-item 保证同时运行。同一 sub-group 中的 work-item 可能有额外的调度保证,并且可以访问额外的功能。
sub-group 是全局索引空间中连续的 work-item 的集合,它们在同一个 VE 线程中执行。当设备编译器编译 kernel 时,多个 work-item 通过向量化被打包到一个 sub-group 中,以便生成的 SIMD 指令流可以同时执行多个 work-item 的任务。正确地将 work-item 划分为 sub-group 可以产生很大的性能差异。
让我们从一个简单的例子开始,来说明 sub-group:
q.submit([&](auto &h) {
sycl::stream out(65536, 256, h);
h.parallel_for(sycl::nd_range(sycl::range{32}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int groupId = it.get_group(0);
int globalId = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroupId = sg.get_group_id()[0];
int sgId = sg.get_local_id()[0];
out << "globalId = " << sycl::setw(2) << globalId
<< " groupId = " << groupId
<< " sgGroupId = " << sgGroupId << " sgId = " << sgId
<< " sgSize = " << sycl::setw(2) << sgSize
<< sycl::endl;
});
});
这个例子的输出可能是这样的:
Device: Intel(R) Gen12HP
globalId = 0 groupId = 0 sgGroupId = 0 sgId = 0 sgSize = 16
globalId = 1 groupId = 0 sgGroupId = 0 sgId = 1 sgSize = 16
globalId = 2 groupId = 0 sgGroupId = 0 sgId = 2 sgSize = 16
globalId = 3 groupId = 0 sgGroupId = 0 sgId = 3 sgSize = 16
globalId = 4 groupId = 0 sgGroupId = 0 sgId = 4 sgSize = 16
globalId = 5 groupId = 0 sgGroupId = 0 sgId = 5 sgSize = 16
globalId = 6 groupId = 0 sgGroupId = 0 sgId = 6 sgSize = 16
globalId = 7 groupId = 0 sgGroupId = 0 sgId = 7 sgSize = 16
globalId = 16 groupId = 0 sgGroupId = 1 sgId = 0 sgSize = 16
globalId = 17 groupId = 0 sgGroupId = 1 sgId = 1 sgSize = 16
globalId = 18 groupId = 0 sgGroupId = 1 sgId = 2 sgSize = 16
globalId = 19 groupId = 0 sgGroupId = 1 sgId = 3 sgSize = 16
globalId = 20 groupId = 0 sgGroupId = 1 sgId = 4 sgSize = 16
globalId = 21 groupId = 0 sgGroupId = 1 sgId = 5 sgSize = 16
globalId = 22 groupId = 0 sgGroupId = 1 sgId = 6 sgSize = 16
globalId = 23 groupId = 0 sgGroupId = 1 sgId = 7 sgSize = 16
globalId = 8 groupId = 0 sgGroupId = 0 sgId = 8 sgSize = 16
globalId = 9 groupId = 0 sgGroupId = 0 sgId = 9 sgSize = 16
globalId = 10 groupId = 0 sgGroupId = 0 sgId = 10 sgSize = 16
globalId = 11 groupId = 0 sgGroupId = 0 sgId = 11 sgSize = 16
globalId = 12 groupId = 0 sgGroupId = 0 sgId = 12 sgSize = 16
globalId = 13 groupId = 0 sgGroupId = 0 sgId = 13 sgSize = 16
globalId = 14 groupId = 0 sgGroupId = 0 sgId = 14 sgSize = 16
globalId = 15 groupId = 0 sgGroupId = 0 sgId = 15 sgSize = 16
globalId = 24 groupId = 0 sgGroupId = 1 sgId = 8 sgSize = 16
globalId = 25 groupId = 0 sgGroupId = 1 sgId = 9 sgSize = 16
globalId = 26 groupId = 0 sgGroupId = 1 sgId = 10 sgSize = 16
globalId = 27 groupId = 0 sgGroupId = 1 sgId = 11 sgSize = 16
globalId = 28 groupId = 0 sgGroupId = 1 sgId = 12 sgSize = 16
globalId = 29 groupId = 0 sgGroupId = 1 sgId = 13 sgSize = 16
globalId = 30 groupId = 0 sgGroupId = 1 sgId = 14 sgSize = 16
globalId = 31 groupId = 0 sgGroupId = 1 sgId = 15 sgSize = 16
在这个例子中,每个 sub-group 有16个 work-item,也就是 sub-group 的大小为 16。这意味着每个线程同时执行 16 个 work-item,32 个 work-item 由两个 VE 线程执行。
默认情况下,编译器使用设备特定信息和一些启发式方法来选择 sub-group 大小。用户可以使用 kernel 属性 intel::reqd_sub_group_size 来指定最大的 sub-group 大小,从而覆盖编译器的选择。有时候,显式地指定 sub-group 大小可能有助于提高性能,但并不总是如此。
q.submit([&](auto &h) {
sycl::stream out(65536, 256, h);
h.parallel_for(sycl::nd_range(sycl::range{32}, sycl::range{32}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(32)]] {
int groupId = it.get_group(0);
int globalId = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroupId = sg.get_group_id()[0];
int sgId = sg.get_local_id()[0];
out << "globalId = " << sycl::setw(2) << globalId
<< " groupId = " << groupId
<< " sgGroupId = " << sgGroupId << " sgId = " << sgId
<< " sgSize = " << sycl::setw(2) << sgSize
<< sycl::endl;
});
});
输出将是:
Device: Intel(R) Gen12HP
globalId = 0 groupId = 0 sgGroupId = 0 sgId = 0 sgSize = 32
globalId = 1 groupId = 0 sgGroupId = 0 sgId = 1 sgSize = 32
globalId = 2 groupId = 0 sgGroupId = 0 sgId = 2 sgSize = 32
globalId = 3 groupId = 0 sgGroupId = 0 sgId = 3 sgSize = 32
globalId = 4 groupId = 0 sgGroupId = 0 sgId = 4 sgSize = 32
globalId = 5 groupId = 0 sgGroupId = 0 sgId = 5 sgSize = 32
globalId = 6 groupId = 0 sgGroupId = 0 sgId = 6 sgSize = 32
globalId = 7 groupId = 0 sgGroupId = 0 sgId = 7 sgSize = 32
globalId = 8 groupId = 0 sgGroupId = 0 sgId = 8 sgSize = 32
globalId = 9 groupId = 0 sgGroupId = 0 sgId = 9 sgSize = 32
globalId = 10 groupId = 0 sgGroupId = 0 sgId = 10 sgSize = 32
globalId = 11 groupId = 0 sgGroupId = 0 sgId = 11 sgSize = 32
globalId = 12 groupId = 0 sgGroupId = 0 sgId = 12 sgSize = 32
globalId = 13 groupId = 0 sgGroupId = 0 sgId = 13 sgSize = 32
globalId = 14 groupId = 0 sgGroupId = 0 sgId = 14 sgSize = 32
globalId = 15 groupId = 0 sgGroupId = 0 sgId = 15 sgSize = 32
globalId = 16 groupId = 0 sgGroupId = 0 sgId = 16 sgSize = 32
globalId = 17 groupId = 0 sgGroupId = 0 sgId = 17 sgSize = 32
globalId = 18 groupId = 0 sgGroupId = 0 sgId = 18 sgSize = 32
globalId = 19 groupId = 0 sgGroupId = 0 sgId = 19 sgSize = 32
globalId = 20 groupId = 0 sgGroupId = 0 sgId = 20 sgSize = 32
globalId = 21 groupId = 0 sgGroupId = 0 sgId = 21 sgSize = 32
globalId = 22 groupId = 0 sgGroupId = 0 sgId = 22 sgSize = 32
globalId = 23 groupId = 0 sgGroupId = 0 sgId = 23 sgSize = 32
globalId = 24 groupId = 0 sgGroupId = 0 sgId = 24 sgSize = 32
globalId = 25 groupId = 0 sgGroupId = 0 sgId = 25 sgSize = 32
globalId = 26 groupId = 0 sgGroupId = 0 sgId = 26 sgSize = 32
globalId = 27 groupId = 0 sgGroupId = 0 sgId = 27 sgSize = 32
globalId = 28 groupId = 0 sgGroupId = 0 sgId = 28 sgSize = 32
globalId = 29 groupId = 0 sgGroupId = 0 sgId = 29 sgSize = 32
globalId = 30 groupId = 0 sgGroupId = 0 sgId = 30 sgSize = 32
globalId = 31 groupId = 0 sgGroupId = 0 sgId = 31 sgSize = 32
有效的 sub-group 大小与设备相关。您可以查询设备获取相关信息:
std::cout << "Sub-group Sizes: ";
for (const auto &s :
q.get_device().get_info<sycl::info::device::sub_group_sizes>()) {
std::cout << s << " ";
}
std::cout << std::endl;
支持的有效 sub-group 大小可能包括:
Device: Intel(R) Gen12HP
Subgroup Sizes: 8 16 32
接下来,我们将展示如何使用 sub-group 来提高性能。
Vectorization and Memory Access
Intel 的图形设备具有多个 VE。每个 VE 都是一个多线程的 SIMD 处理器。编译器生成 SIMD 指令,将一个 sub-group 中的多个 work-item 打包,以便在 VE 线程中同时执行。编译器选择的 SIMD 宽度(即 sub-group 大小)基于设备特征和启发式方法,或由 kernel 显式指定,可以是 8、16 或 32。
在给定 SIMD 宽度的情况下,最大化 SIMD 通道利用率可以获得最佳的指令性能。如果一个或多个通道(或 kernel 实例或 work-item)发生分歧,线程在路径合并之前执行两个分支路径,增加动态指令计数。SIMD 分歧对性能产生负面影响。编译器努力最小化分歧,但如果可能的话,最好在源代码中避免分歧。
work-item 中内存的访问方式会影响 sub-group 中内存的访问方式或 SIMD 通道的利用方式。在 work-item 中访问连续内存通常不是最佳选择。例如:
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N / 16}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
i = i * 16;
for (int j = i; j < (i + 16); j++) {
data[j] = -1;
}
});
});
q.wait();
这个简单的 kernel 初始化了一个 1024 x 1024 的整数数组。每个 work-item 初始化 16 个连续的整数。假设编译器选择的 sub-group 大小为 16,则每个 sub-group 或线程中初始化 256 个整数。然而,16 个 SIMD 通道中的存储是分散的。
与其在一个 work-item 中初始化 16 个连续的整数,不如在一个 SIMD 指令中初始化 16 个连续的整数更有效率。
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N / 16}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
i = (i / sgSize) * sgSize * 16 + (i % sgSize);
for (int j = 0; j < sgSize * 16; j += sgSize) {
data[i + j] = -1;
}
});
});
我们在示例中使用了内存写入,但同样的技术也适用于内存读取。
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
int *data2 = sycl::malloc_shared<int>(N, q);
memset(data2, 0xFF, sizeof(int) * N);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N / 16}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
i = i * 16;
for (int j = i; j < (i + 16); j++) {
data[j] = data2[j];
}
});
});
这个 kernel 将一个 1024 x 1024 的整数数组复制到另一个相同大小的整数数组中。每个 work-item 复制 16 个连续的整数。然而,从 data2 中读取的数据是聚集的,而存储到 data 中的数据是分散的。更改代码在每个 sub-group 而不是每个 work-item 中读取和存储中的连续整数将更有效。
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
int *data2 = sycl::malloc_shared<int>(N, q);
memset(data2, 0xFF, sizeof(int) * N);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N / 16}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
i = (i / sgSize) * sgSize * 16 + (i % sgSize);
for (int j = 0; j < sgSize * 16; j += sgSize) {
data[i + j] = data2[i + j];
}
});
});
Maximizing Memory Bandwidth Utilization
在上面的示例中,每个 work-item 在每次循环迭代中加载和存储 1 个整数或 4 个字节 (data[i + j] = data2[i + j];),或者每个向量化内存操作加载/存储 64 个字节(假设 sub-group 大小为 16),使内存带宽不饱和。
增加每个 work-item 在一次内存操作中加载或存储的有效负载或数据大小将导致更好的带宽利用率。
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
int *data2 = sycl::malloc_shared<int>(N, q);
memset(data2, 0xFF, sizeof(int) * N);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N / 16}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
i = (i / sgSize) * sgSize * 16 + (i % sgSize) * 4;
for (int j = 0; j < 4; j++) {
sycl::vec<int, 4> x;
sycl::vec<int, 4> *q =
(sycl::vec<int, 4> *)(&(data2[i + j * sgSize * 4]));
x = *q;
sycl::vec<int, 4> *r =
(sycl::vec<int, 4> *)(&(data[i + j * sgSize * 4]));
*r = x;
}
});
});
每个 work-item 在每次循环迭代中加载/存储一个 sycl::vec<int,4> 而不是一个整数。读取/写入 256 个连续字节的内存(假设 sub-group 大小为 16),每个向量化内存操作的有效负载增加了四倍。
最大带宽因硬件而异。可以使用 Intel® VTune Profiler 来测量带宽并找到最佳大小。
然而,使用向量类型可能会增加寄存器压力。建议仅在寄存器不溢出时使用长向量。请参阅“寄存器化和避免寄存器溢出”一章,了解避免寄存器溢出的技巧。
Memory Block Load and Store
Data Sharing
由于 sub-group 中的 work-item 在同一线程中执行,因此在 work-item 之间共享数据更有效率,即使数据对每个 work-item 是私有的。在 sub-group 中共享数据比使用共享本地内存或 SLM 在 work-group 中共享数据更有效率。在 sub-group 中的 work-item 之间共享数据的一种方法是使用 shuffle 函数。
constexpr size_t BLOCK_SIZE = 16;
sycl::buffer<uint, 2> m(matrix.data(), sycl::range<2>(N, N));
auto e = q.submit([&](auto &h) {
sycl::accessor marr(m, h);
sycl::local_accessor<uint, 2> barr1(
sycl::range<2>(BLOCK_SIZE, BLOCK_SIZE), h);
sycl::local_accessor<uint, 2> barr2(
sycl::range<2>(BLOCK_SIZE, BLOCK_SIZE), h);
h.parallel_for(
sycl::nd_range<2>(sycl::range<2>(N / BLOCK_SIZE, N),
sycl::range<2>(1, BLOCK_SIZE)),
[=](sycl::nd_item<2> it) [[intel::reqd_sub_group_size(16)]] {
int gi = it.get_group(0);
int gj = it.get_group(1);
auto sg = it.get_sub_group();
uint sgId = sg.get_local_id()[0];
uint bcol[BLOCK_SIZE];
int ai = BLOCK_SIZE * gi;
int aj = BLOCK_SIZE * gj;
for (uint k = 0; k < BLOCK_SIZE; k++) {
bcol[k] = sg.load(marr.get_pointer() + (ai + k) * N + aj);
}
uint tcol[BLOCK_SIZE];
for (uint n = 0; n < BLOCK_SIZE; n++) {
if (sgId == n) {
for (uint k = 0; k < BLOCK_SIZE; k++) {
tcol[k] = sg.shuffle(bcol[n], k);
}
}
}
for (uint k = 0; k < BLOCK_SIZE; k++) {
sg.store(marr.get_pointer() + (ai + k) * N + aj, tcol[k]);
}
});
});
这个 kernel 转置一个 16 x 16 的矩阵。它看起来比前面的例子更复杂,但思想很简单: 一个 sub-group 加载一个 16 x 16 的子矩阵,然后使用 sub-group shuffle 函数对子矩阵进行转置。只有一个子矩阵,子矩阵就是矩阵,所以只需要一个 sub-group。更大的矩阵,比如 4096 x 4096,可以使用相同的技术进行转置:每个 sub-group 加载一个子矩阵,然后使用 sub-group shuffle 函数对子矩阵进行转置。这留给读者作为练习。
SYCL 提供了多种 sub-group shuffle 函数的变体。每种变体都针对特定设备上的特定用途进行了优化。使用这些优化过的函数(如果它们符合您的需求)会是更好的选择,而不是创建您自己的函数。
Sub-Group Size vs. Maximum Sub-Group Size
到目前为止,在我们的示例中,work-group 大小可以被 sub-group 大小整除,work-group 大小和 sub-group 大小(由用户指定或由编译器自动选择)都是 2 的幂。如果 work-group 大小可以被最大 sub-group 大小整除且两个大小都是 2 的幂,则 sub-group 大小和最大 sub-group 大小相同。但是,如果 work-group 大小不能被 sub-group 大小整除会发生什么呢? 请看以下示例:
auto e = q.submit([&](auto &h) {
sycl::stream out(65536, 128, h);
h.parallel_for(sycl::nd_range<1>(7, 7),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int i = it.get_global_linear_id();
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgMaxSize = sg.get_max_local_range()[0];
int sId = sg.get_local_id()[0];
int j = data[i];
int k = data[i + sgSize];
out << "globalId = " << i << " sgMaxSize = " << sgMaxSize
<< " sgSize = " << sgSize << " sId = " << sId
<< " j = " << j << " k = " << k << sycl::endl;
});
});
q.wait();
这个示例的输出是这样的:
globalId = 0 sgMaxSize = 16 sgSize = 7 sId = 0 j = 0 k = 7
globalId = 1 sgMaxSize = 16 sgSize = 7 sId = 1 j = 1 k = 8
globalId = 2 sgMaxSize = 16 sgSize = 7 sId = 2 j = 2 k = 9
globalId = 3 sgMaxSize = 16 sgSize = 7 sId = 3 j = 3 k = 10
globalId = 4 sgMaxSize = 16 sgSize = 7 sId = 4 j = 4 k = 11
globalId = 5 sgMaxSize = 16 sgSize = 7 sId = 5 j = 5 k = 12
globalId = 6 sgMaxSize = 16 sgSize = 7 sId = 6 j = 6 k = 13
sub-group 大小为七,尽管最大 sub-group 大小仍然为 16!最大 sub-group 大小实际上是 SIMD 宽度,所以它不会改变,但是 sub-group 中的 work-item 少于八个,所以 sub-group 大小为七。因此,当您的 work-group 大小不能被最大 sub-group 大小整除时要小心。最后一个 work-item 较少的 sub-group 可能需要特殊处理。
2.3.2. Removing Conditional Checks
2.3.3. Registerization and Avoiding Register Spills
Registers and Performance
寄存器是内存层次结构中最快的存储器。尽可能长时间地将数据保存在寄存器中对性能至关重要。然而,寄存器空间有限,比内存空间小得多。例如,当前一代 Intel® GPU 每个 XVE 线程有 128 个通用寄存器,每个默认宽度为 32 字节。尽管编译器旨在将尽可能多的变量分配给寄存器,但有限数量的寄存器只能在执行过程中的某一时刻分配给一小组变量。一个特定的寄存器可以在不同时间保存不同的变量,因为不同时间需要不同的变量集合。如果没有足够的寄存器来保存所有变量,则寄存器可能会溢出,或者当前在寄存器中的某些变量可以移动到内存中以腾出空间给其他变量。
在 SYCL 中,编译器将寄存器分配给 work-item 中的私有变量。一个sub-group中的多个work-item被打包到一个XVE线程中。默认情况下,编译器使用寄存器压力作为选择SIMD宽度或sub-group大小的参考因素之一。如果没有显式指定sub-group大小,高寄存器压力可能导致较小的sub-group大小(例如8而不是16),这也可能导致寄存器溢出或导致某些变量无法提升到寄存器。
如果sub-group大小或SIMD宽度不是硬件支持的最大值,则硬件可能无法充分利用。寄存器溢出可能导致性能显著下降,特别是当溢出发生在热点循环内部时。当变量未提升到寄存器时,对这些变量的访问会导致内存访问显著增加。
尽管编译器使用智能算法在寄存器中分配变量并最小化寄存器溢出,但开发人员的优化可以帮助编译器做得更好,并且通常会产生很大的性能差异。
Optimization Techniques
以下技术可以减小寄存器压力:
- 尽可能缩短私有变量的生命周期。
尽管编译器调度指令并优化变量的距离,但在某些情况下,在源码中将加载和使用相同变量移动得更近或删除某些依赖关系可以帮助编译器做得更好。
- 避免过度的循环展开。
循环展开可以让编译器看到更多指令调度优化的机会,从而提高性能。然而,展开引入的临时变量可能会增加寄存器分配的压力并导致寄存器溢出。实践中的好方法是比较带有和不带有循环展开以及不同次数展开的性能,以决定是否应该展开循环或展开多少次。
- 优先选择使用 USM 指针。
Buffer accessor 方式的访问占用的空间比 USM 指针多。如果可以在 USM 指针和 buffer accessor 方式之间选择,请选择使用 USM 指针。
- 对于计算开销小的值,按需重新计算,而不是将它一直保留为变量,否则它会被长时间保存在寄存器中。
- 避免使用大数组或大结构,或者将大结构的数组拆分为多个小结构的数组。
例如,一个 sycl::float4 的数组:
sycl::float4 v[8];
可以拆分为 4 个 float 数组:
float x[8]; float y[8]; float z[8]; float w[8];
所有或部分 4 个 float 数组比 sycl::float4 数组更有可能被分配到寄存器中。
- 将一个大循环拆分为多个小循环,以减少同时活跃的变量数量。
- 如果可能,选择较小尺寸的数据类型。
- 不要将私有变量声明为 volatile。
- 在 sub-group 中共享寄存器。
- 如果可能,使用 sub-group 块来加载/存储。
- 尽可能使用共享本地内存(SLM)。
这里列举了一些技术,并不详尽。
本章的其余部分将展示如何在实际示例中应用这些技术,重点是最后五项。
Choosing Smaller Data Types
2.3.4. Considerations for Selecting Work-Group Size
在 SYCL 中,您可以为 nd_range kernel 选择 work-group 大小。work-group 的大小对计算资源,向量通道和 work-item 之间的通信的利用率具有重要影响。同一 work-group 中的 work-item 可能具有对 SLM 和硬件同步功能等硬件资源的访问权限,这将使它们比跨 work-group 的 work-item 运行和通信更高效。因此,通常应选择加速器支持的最大 work-group 大小。可以通过调用 device::get_info<cl::sycl::info::device::max_work_group_size>() 来查询最大 work-group 大小。
为了说明 work-group 大小选择的影响,请查看以下归约 kernel,它遍历一个大型向量以添加其中所有元素。运行 kernel 的函数以 work-group-size 和 sub-group-size 为入参,这使您可以使用不同的值进行实验。当 kernel 使用不同的 work-group 大小值调用时,可以从报告的时间统计中看到性能差异。
void reduction(sycl::queue &q, std::vector<int> &data, std::vector<int> &flush,
int iter, int work_group_size) {
const size_t data_size = data.size();
const size_t flush_size = flush.size();
int sum = 0;
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
// int vec_size =
// q.get_device().get_info<sycl::info::device::native_vector_width_int>();
int num_work_items = data_size / work_group_size;
sycl::buffer<int> buf(data.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
sycl::buffer<int> sum_buf(&sum, 1, props);
init_data(q, buf, data_size);
double elapsed = 0;
for (int i = 0; i < iter; i++) {
q.submit([&](auto &h) {
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(1, [=](auto index) { sum_acc[index] = 0; });
});
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
// reductionMapToHWVector main begin
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] {
auto v =
sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
sum_acc[0]);
int sum = 0;
int glob_id = item.get_global_id();
int loc_id = item.get_local_id();
for (unsigned int i = glob_id; i < data_size; i += num_work_items)
sum += buf_acc[i];
scratch[loc_id] = sum;
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (loc_id < i)
scratch[loc_id] += scratch[loc_id + i];
}
if (loc_id == 0)
v.fetch_add(scratch[0]);
});
});
q.wait();
elapsed += timer.Elapsed();
sycl::host_accessor h_acc(sum_buf);
sum = h_acc[0];
}
elapsed = elapsed / iter;
std::string msg = "with work-groups=" + std::to_string(work_group_size);
check_result(elapsed, msg, sum);
} // reduction end
在下面的代码中,上述 kernel 被调用了两个不同的值: 2*vec-size 和加速器支持的最大可能 work-group 大小。当 work-group 大小等于 2*vec-size 时,kernel 的性能将低于 work-group 大小为最大可能值时的性能。
int vec_size = 16;
int work_group_size = vec_size;
reduction(q, data, extra, 16, work_group_size);
work_group_size =
q.get_device().get_info<sycl::info::device::max_work_group_size>();
reduction(q, data, extra, 16, work_group_size);
在没有使用 barrier 或原子操作的情况下,work-group 大小不会影响性能。为了说明这一点,请参考以下 vec_copy kernel,其中没有使用原子操作或 barrier。
void vec_copy(sycl::queue &q, std::vector<int> &src, std::vector<int> &dst,
std::vector<int> &flush, int iter, int work_group_size) {
const size_t data_size = src.size();
const size_t flush_size = flush.size();
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
int num_work_items = data_size;
double elapsed = 0;
{
sycl::buffer<int> src_buf(src.data(), data_size, props);
sycl::buffer<int> dst_buf(dst.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
for (int i = 0; i < iter; i++) {
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
q.submit([&](auto &h) {
sycl::accessor src_acc(src_buf, h, sycl::read_only);
sycl::accessor dst_acc(dst_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item)
[[intel::reqd_sub_group_size(16)]] {
int glob_id = item.get_global_id();
dst_acc[glob_id] = src_acc[glob_id];
});
});
q.wait();
elapsed += timer.Elapsed();
}
}
elapsed = elapsed / iter;
std::string msg = "with work-group-size=" + std::to_string(work_group_size);
check_result(elapsed, msg, dst);
} // vec_copy end
在下面的代码中,上述 kernel 调用了不同的 work-group 大小。所有上述对 kernel 的调用都将具有类似的运行时间,这表明 work-group 大小对性能没有影响。原因是当 work-group 中没有 barrier 或 SLM 时,work-group 内创建的线程和来自不同 work-group 的线程在调度和资源分配方面表现相似。
int vec_size = 16;
int work_group_size = vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 2 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 4 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 8 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 16 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
在某些加速器中,由于线程在处理元素之间的调度方式,需要最小的 sub-group 大小才能获得良好的性能。在这种情况下,当 sub-group 数量小于最小值时,您可能会看到很大的性能差异。上面第3行对 kernel 的调用只有一个 sub-group,而第5行的调用有两个 sub-group。在一次执行两个 sub-group 调度的加速器上测试,这两个 kernel 调用的计时将显示出明显的性能差异。
Tuning Kernels with Local and Global Work-group Sizes in OpenMP Offload Mode
上述用于调整 SYCL 中加速器设备上 kernel 性能的方法也适用于通过 OpenMP 在 offload 模式下的实现。可以使用 OpenMP 指令自定义应用程序 kernel,以使用适当的 work-group 大小。但是,这可能需要对代码进行大量修改。OpenMP 实现提供了使用环境变量自定义调整 kernel 的可选项。可以使用两个环境变量 – OMP_THREAD_LIMIT 和 OMP_NUM_TEAMS 来自定义应用程序中 kernel 的本地和全局 work-group 大小,如下所示,它们有助于设置本地 work-group 大小 (LWS) 和全局 work-group 大小 (GWS):
LWS = OMP_THREAD_LIMIT
GWS = OMP_THREAD_LIMIT * OMP_NUM_TEAMS
借助以下归约 kernel 示例,我们展示了在加速器设备上调整 kernel 性能时使用 LWS 和 GWS 的方法。
int N = 2048;
double* A = make_array(N, 0.8);
double* B = make_array(N, 0.65);
double* C = make_array(N*N, 2.5);
if ((A == NULL) || (B == NULL) || (C == NULL))
exit(1);
int i, j;
double val = 0.0;
#pragma omp target map(to:A[0:N],B[0:N],C[0:N*N]) map(tofrom:val)
{
#pragma omp teams distribute parallel for collapse(2) reduction(+ : val)
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
val += C[i * N + j] * A[i] * B[j];
}
}
}
printf("val = %f10.3\n", val);
free(A);
free(B);
free(C);
例如,通过配置 OMP_THREAD_LIMIT = 1024 和 OMP_NUM_TEAMS = 120, 分别将 LWS 和 GWS 参数设置为 1024 和 122880。
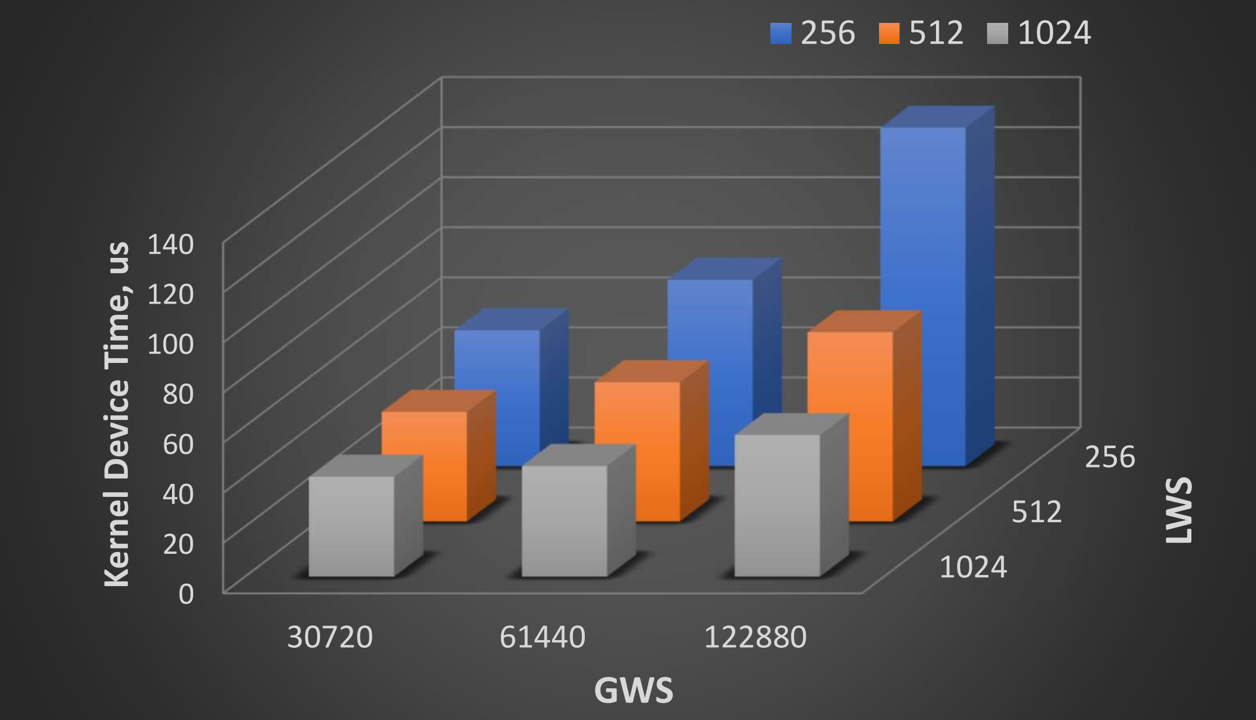
上图显示,此 kernel 的最佳性能来自 LWS = 1024 and GWS = 30720,这对应于 OMP_THREAD_LIMIT = 1024 和 OMP_NUM_TEAMS = 30。这些环境变量将为通过 OpenMP offload 的所有 kernel 将 LWS 和 GWS 值设置为固定数字。但是,这些环境变量不会影响 OneMKL 等高度调优的库 kernel 使用的 LWS 和 GWS。