Intel CHA 模块监控
1. 简介
1.1. CHA
CHA(LLC coherence engine and Home agent)将 cache agent 和 home agent(HA)包含在单一模块中。 CHA是 uncore 与处理器核心接口,也是末级缓存(Last Level Cache)的连接接口。 当处理器核心或者 IIO DMA(Direct Memory Access)发起访问 LLC 需求时,会通过网络内部访问 CHA,随后 CHA 对访问请求做出应答,并且保证在 Socket 上共享此 LLC 的核心或 IIO 设备中数据的一致性。 Intel 中 LLC 在核心(IA)外部,每个占有 1.125 MB 大小 LLC 容量,核心内部有附加缓存大小,CHA 只负责维护此部分缓存(LLC)同步过程。
1.2. 设备与核心间数据读写
CHA 主要功能是提供 PCIe 带宽读写监控。 在 IO 过程中,例如 NIC 网卡和硬盘等设备在与核心之间进行通信时,需要对缓存和内存等数据进行访问。
以 NIC 网卡为例,主要数据流可以分为设备数据读取和设备数据写入两种。
- 在设备数据写入过程中,首先会在软件运行中创建数据包,其中涉及所需数据填充的缓存区(内存地址),以及 NIC 命令填充的控制结构。由于数据并不在缓存中,这些操作会导致缓存未命中,导致数据从内存读取并进入缓存系统中。 随后 NIC 收到传输操作指令并开始读取数据。由于数据由运行在CPU上应用创建,数据会驻留在缓存系统中。此外,由于 NIC 在其 PCIe 互联上执行还会导致数据从缓存中被逐出(如图2.1)。使得一次读取操作导致两次到三次内存访问过程。
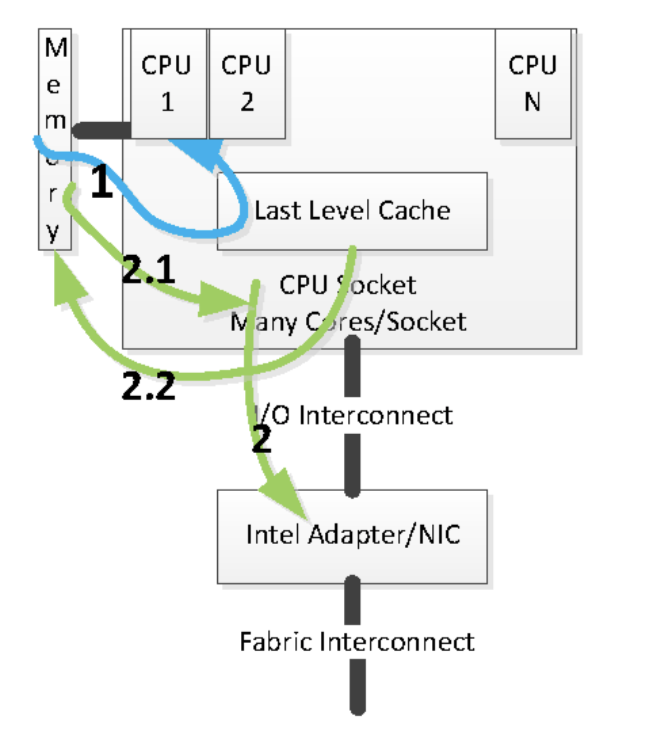
- 当这些数据从网卡传入主机时,数据传递操作会令 NIC 将数据传输到主机内存,当传输的数据恰好在缓存中时,这些缓存会失效。当CPU运行的应用开始读取数据时,由于数据并不在缓存中,会使得数据再次由内存读取到缓存系统中。
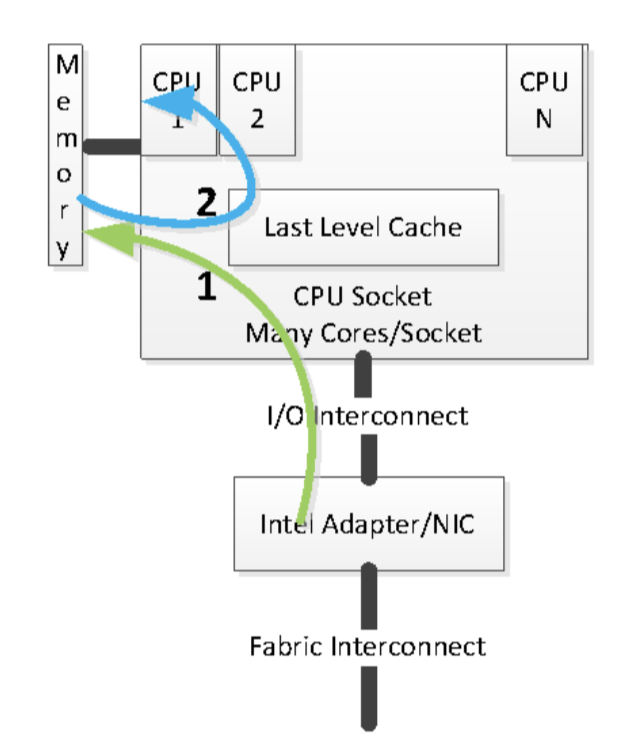
为了提高IO数据处理效率,Intel 推出了 DDIO 技术,可以实现网卡与处理器缓存直接通信,避免使用系统内存。 DDIO 使处理器缓存成为了数据主要目的地和来源,通过避免对内存进行多次读取和写入,可以减少IO造成延迟,增加带宽并降低功耗。 以数据写入设备为例,当创建数据包进行相关数据写入时,直接可在缓存系统中进行操作,不必再从内存中获取数据。 在网卡发起的内存读操作时不再引起数据驱逐,可以被软件重复使用。
1.3. CHA 性能监控事件
2. 性能监控模块
Intel CHA 监控模块属于 Uncore 部分,对于不同型号 Ucore 模块 PMU 单元存在着一定区别,下面将对 SkyLake 和 IceLake 等平台分别进行介绍。
2.1. SkyLake
根据 Intel Skylake Uncore 监控手册1,Skylake 最多包含 28 个 CHA 模块。每个 CHA 模块支持 4 个 48 位 PMC(Cn_MSR_PMON_CTR{3:0})及对应事件选择计数器(Cn_MSR_PMON_CTL{3:0})。

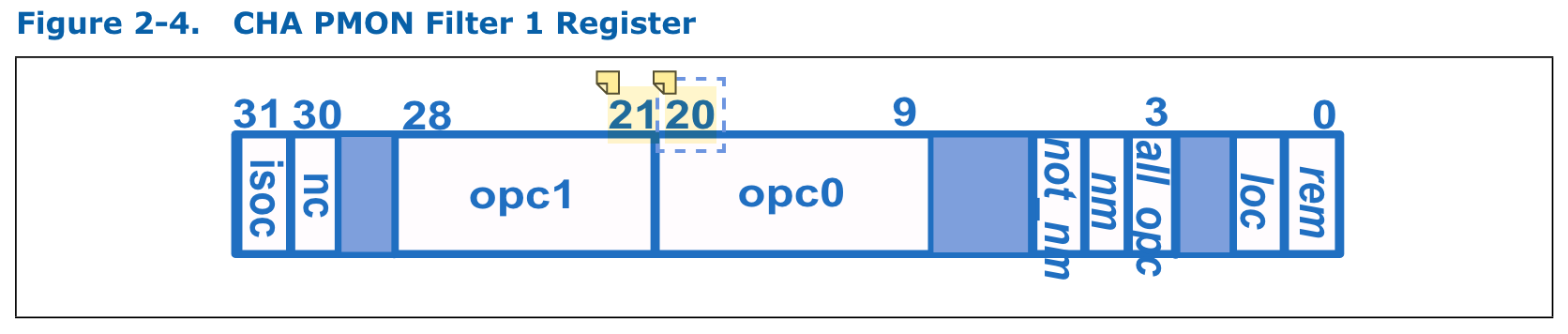
某些 Uncore 性能事件,如传输事件等,需要附加细节通过 filter 寄存器进行选择。 每个 CHA 提供了两个 filter,但是每次只能对一个进行编程。
除上述 4 个 PMC + 4 CTL + 2 Filter 之外,每个 CHA 中还包含一个 Box 控制寄存器(Cn_MSR_PMON_BOX_CTL)和状态寄存器(Cn_MSR_PMON_BOX_STATUS)。 上述 CHA 模块中性能计数器都是 MSR 类型,在Intel Skylake Uncore 监控手册1中表 Table 2-61 提供了不同 CHA 中对应寄存器地址。
- Cn_MSR_PMON_BOX_CTL 为 32 位寄存器,可以控制 CHA 内监控模块是否启动,并可以将 PMC 和 CTL 寄存器清零。
- Cn_MSR_PMON_CTL{3-0} 寄存器也为 32 位,与普通性能计数器功能类似,只能通过 ev_sel 和 umask 位对监控事件进行选择。
- Cn_MSR_PMON_CTR{3-0} 寄存器为 48 位。
- Cn_MSR_PMON_BOX_FILTER0 和 Cn_MSR_PMON_BOX_FILTER1 为 32 位,对于 PCIe 带宽事件 TOR_INSERTS 等通过 opcode 位对特定队列请求进行过滤。
2.2. IceLake
Icelake 平台包含的 CHA 模块增加到 40 个,对应监控寄存器个数与 skylake 相同。在事件选择寄存器中,长度倍扩展到 64 位。增加的 umask_ext 位可以对 TOR_INSERTS/OCCUPANCY 或 LLC_LOOKUP 等事件中特殊事件进一步指定。
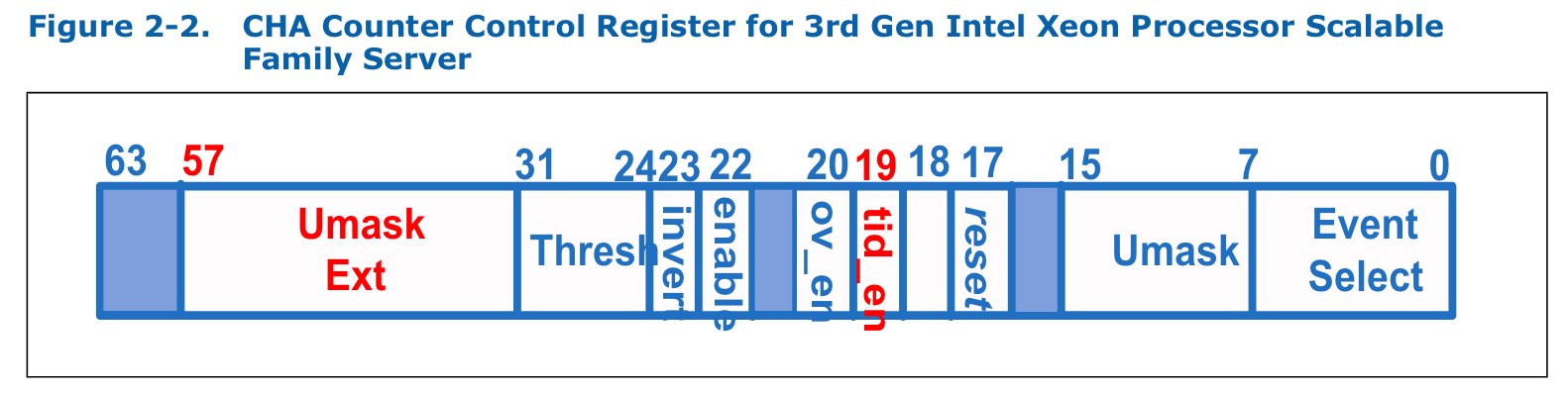
对于 TOR_INSERT/OCCUPANCY 事件,opcode 位与 skylake 平台 filter 中 opcode 位功能相同。
CHA 寄存器地址可以参考 IceLake Uncore 监控手册中表 1-92。 需要注意的是,大部分相邻 CHA 模块寄存器地址差异为 0xE,但是在 CHA 18 和 CHA 34 出现地址跳跃情况,其中 CHA 17 和 CHA 18 之间差异为两倍 0xE,即 0x1C。
3. 性能监控事件
3.1. Intel 平台 PCIe 带宽监控
在 Intel 平台 PCIe 带宽监控事件可以分为三类:
第一类为 PCIe 设备或核心读取事件
- RdCur(Read current)代表 PCIe 设备从内存系统中读取数据,包括 Hit 和 Miss 两类。Hit 代表读取的数据存在于 LLC 上,而 Miss 为从内存系统中读取 Cachelines 数量。
- DRd(Demand Data Read)为 PCIe 或核心从内存系统中读取,而 Cachelines 在 LLC 中申请。
- CRd(Demand Code Read)与 DRd 类似,包括 CPU 读取 LLC 中指令。
第二类为 PCIe 写事件
- ItoM(Request Invalidate Line) 表示 PCIe 将完整 Cachelines 写入内存系统中,也包括 Hit 和 Miss 两种情况,Hit 表示 LLC 已经包含要写入的 Cachelines,而 Miss 表示 Cachelines 已经申请,但是无法写入。
- RFO(Demand Data RFO) 表示 PCIe 设备将不完整 Cachelines 写入内存系统,类似的,Hit 表示 Cachelines 已经存在于 LLC 上,而 Miss 表示 Cachelines 已经使用,需要重新写入。
第三类为 CPU 写入内存映射空间(MMIO)事件
- PRd(Partial Reads)为 CPU 通过 MMIO 映射从 PCIe 设备中读取数据。
- Wil(Write Invalidate Line - Partial)为 CPU 通过 MMIO 映射将数据写入 PCIe 设备中。
3.2. Skylake
Skylake 平台 PCIe 带宽监控事件为 TOR_INSERTS,对应事件编号为 0x35。在事件选择寄存器中,umask 位指定了对应事件为 Miss/Hit 或者读写请求由核心(IA)/IO设备生成(1表2-98)。
为了监控 PCIe 设备,可以指定所有由 IO 设备申请的事件,此时对应 umask 编码为 b00110100 = 0x34。
对于不同监控事件,如 RdCur、DRd、CRd 等,需要对 Filter1 的 opc0 位进行指定。不同事件对应编码为
| opc | opc 编码 | 说明 |
|---|---|---|
| RdCur | 0x21E | Read current - Read Current requests from IIO. Used to read data without changing state. |
| DRd | 0x202 | Demand Data Read - Full cache-line read requests from core for lines to be cached in S or E, typically for data |
| CRd | 0x201 | Demand Code Read - Full cache-line read requests from core for lines to be cached in S, typically for code |
| ItoM | 0x248 | Request Invalidate Line - Request Exclusive Ownership of cache line |
| RFO | 0x200 | Demand Data RFO - Read for Ownership requests from core for lines to be cached in E |
| PRd | 0x207 | Partial Reads (UC) - Partial read requests of 0-32B (IIO can be up to 64B). Uncacheable. |
| WiL | 0x20F | Write Invalidate Line - Partial |
需要注意的是,由于 Filter1 每次只能对单个事件进行监控,因此为了实现对所有事件监控,必须使用多路复用方法实现。 对于PCIe带宽,是以 PCIe 设备为对象定义读写操作:
- 对于 PCIe 读带宽,包括 RdCur + RFO + CRd + DRd 等四个事件;
- 对于 PCIe 写带宽则包括 RFO + ItoM。
3.3. Icelake
在 Icelake Uncore 监控手册中表 2-132 中,定义了 TOR_INSERTS 事件对应扩展事件编号,包括 umask 和 umask_ext 等位置对应编码。
| opcode | umask | umask_ext | 说明 |
|---|---|---|---|
| IO_MISS_PCIRDCUR | b00000100 | 0xC8F3FE | PCIRdCurs issued by IO Devices that missed the LLC |
| IO_HIT_ITOMCACHENEAR | b00000100 | 0xCD43FD | ItoMCacheNears, indicating a partial write request, from IO Devices that hit the LLC |
| IO_MISS_ITOM | b00000100 | 0xCC43FE | ItoMs issued by IO Devices that missed the LLC |
| IO_HIT_PCIRDCUR | b00000100 | 0xC8F3FD | PCIRdCurs issued by IO Devices that hit the LLC |
| IO_HIT_RFO | b00000100 | 0xC803FD | RFOs issued by IO Devices that hit the LLC |
| IO_MISS_RFO | b00000100 | 0xC803FE | RFOs issued by IO Devices that missed the LLC |
| IO_MISS_ITOMCACHENEAR | b00000100 | 0xCD43FE | ItoMCacheNears, indicating a partial write request, from IO Devices that missed the LLC |
| IO_HIT_ITOM | b00000100 | 0xCC43FD | ItoMs issued by IO Devices that Hit the LLC |
| IO_PCIRDCUR | b00000100 | 0xC8F3FF | PCIRdCurs issued by IO Devices |
| IO | b00000100 | 0xC001FF | All requests from IO Devices |
| IO_HIT | b00000100 | 0xC001FD | All requests from IO Devices that hit the LLC |
| IO_MISS | b00000100 | 0xC001FE | All requests from IO Devices that missed the LLC |
根据 Intel pcm 监控,
- PCIe 读带宽为 IO_HIT_PCIRDCUR + IO_MISS_PCIRDCUR;
- PCIe 写带宽大小为 IO_HIT_ITOM + IO_MISS_ITOM + IO_HIT_ITOMCACHENEAR + IO_MISS_ITOMCACHENEAR。