Intel 平台性能监控
1. 简介
如今,性能监控单元(Performance Monitor Unit,PMU)在所有高端处理器中都能找到。 PMU 基本上是处理器内置的硬件,用于测量硬件运行时性能参数,包括指令周期、缓存命中、缓存未命中、分支未命中等参数。 这些信息取决于硬件性能监控单元(处理器)提供的支持情况。 由于测量是由硬件完成的,因此占用硬件资源开销非常有限。
本文中,我们将深入了解英特尔 IA-32 的 PMU,并从使用层面了解其工作原理。 如何配置这些 PMU 寄存器以及如何将它们用于不同类型的性能测量。 然后我们将研究如何利用性能监控系统,进行实用程序的性能分析工作。
2. 最简单的 PMU
在现代 CPU 流水线中,包括取值(Fetch)、解码(Decode)、发射(Issued)、执行(Execution)、回退(Retired)等步骤。 CPU中包含时钟发生器向系统每个部分发送信号,每个模块收到脉冲信号后完成循环,进入下个阶段。
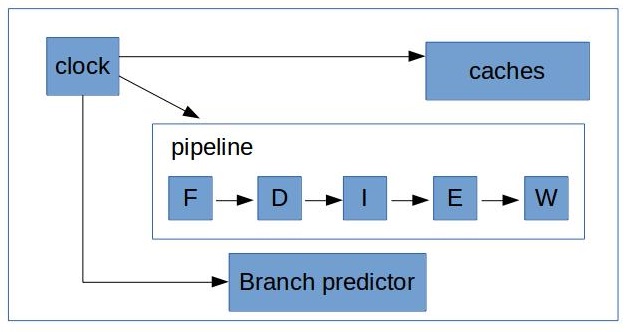
最简单的计数器就是在信号发生器附近增加一个性能计数器(Performance Monitor Counter,PMC),并对脉冲信号进行计数。 实际上,计数器只是一个硬件寄存器,通过不定期的对此寄存器值进行读取,可以了解执行时钟周期个数。
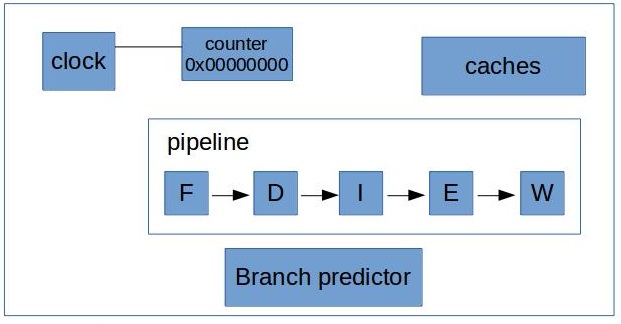
现代 CPU 中包含模块众多,没法每个部件都设置一个固定计数器。 为此,可以将计数器与感兴趣的模块相连,并且增加一个配置寄存器,来控制PMC使用哪个通道对模块运行进行监控。 在实践中,不可能将PMC与CPU中每个模块相连。因此架构师会尝试将 PMC 放在芯片不同位置上,尽可能靠近它们需要监控的模块。 此外还会将每个组件至少与两个不同PMC相连,保证能够同时计算两个不同的事件。
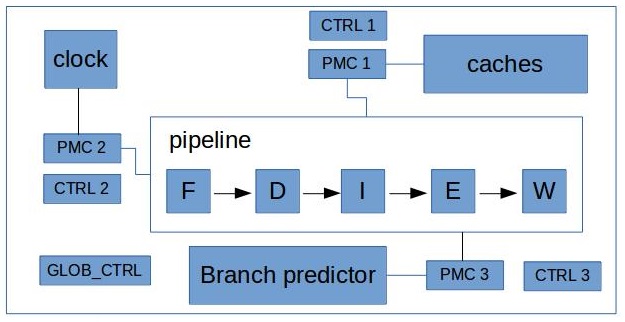
3. Intel PMU
在 Intel Pentium 处理器开始,通过引入性能监控计数器 MSRs(Model-Specific Register)实现了性能监控功能。 Intel IA-32 架构中的 PMU 由两种类型的寄存器或模型特定寄存器 (MSR) 组成。 它们被称为型号特定,因为每个处理器型号都有一些不同于其他型号的寄存器,即使是来自同一家公司。 这两种类型是性能事件选择寄存器和性能监控计数器 (PMC)。 测量性能事件需要对事件选择寄存器进行编程。 性能事件在 PMC 中计数。 因此,为了测量性能事件,我们需要事件选择器和 PMC。
4. 性能监控类型
4.1. 计数
在这种类型的测量中,在给定时间段内发生的事件总数在持续时间结束时汇总和报告。 性能控制寄存器被设置用于对所需事件进行计数,并在监视周期结束后读取这些寄存器的值。
4.1.1. 事件选择寄存器
- 事件选择字段(位 0-7):
该字段用于选择检测需要监控的性能监控事件的逻辑单元。所以这个字段要填写的值是由架构决定的。
- 单元掩码 (UMASK) 字段(位 8-15):
事件选择字段选择的逻辑单元可能能够监控多个事件。因此,此 UMASK 字段用于选择可由逻辑单元监视的事件之一。因此根据选择的逻辑单元,UMASK 字段可能有一个固定值或多个值,这取决于架构。
- USR 标志(位 16):
如果设置了该标志,则该标志告诉逻辑单元监视当处理器以用户权限级别(即级别 1 到级别 3)运行时发生的事件。
- 操作系统标志(位 17):
如果设置了该标志,则该标志告诉逻辑单元监视在处理器以最高特权级别(即级别 0)运行时发生的事件。该标志和 USR 标志可以一起用于监视或计数所有事件。
- E(边缘检测)(位 18):
设置此标志时计算所选事件从低状态变为高状态的次数。
- PC(引脚控制)(位 19):
设置此标志时,计数器会递增并在受监控事件发生时触发 PMi 引脚。如果未设置,它仅在计数器溢出时切换 PMi 引脚。
- INT(APIC 中断使能)标志(位 20):
设置此标志时,处理器会在性能监控计数器溢出时引发中断。
- EN(启用计数器)标志(位 22):
此标志设置时启用事件的性能监控计数器,清除时禁用计数器。
- INV(反转)标志(位 23):
设置此标志会反转 CMASK 比较的输出。这使用户能够设置 CMASK 和计数器值之间的大于和小于比较。
- CMASK(计数器掩码)字段(位 24 到 31):
如果该字段的值大于零,则将该值与一个时钟周期内生成的事件数进行比较。如果生成的事件大于 CMASK 值,则计数器递增 1,否则计数器不递增。
4.1.2. 面临的挑战:
- 如果要监视的事件数大于处理器提供的计数器总数。
- 如果要监视的两个不同事件由处理器中存在的相同数字逻辑测量。
解决方法:
多路复用用于解决上述问题。
在第一种情况下,由于计数器的数量较少,事件共享同一计数器的时间,即时分复用。这意味着一个事件不会在整个测量持续时间内获得专用计数器。相反,在整个测量周期内,在较短的持续时间内对事件进行多次测量。在测量持续时间结束时,还会记录实际测量周期,并针对整个测量周期调整聚合事件计数。
在第二种情况下,使用与第一种情况相同的技术。唯一的区别是这次数字逻辑单元被时间复用以测量不同的事件。
限制:
尽管多路复用解决了一些问题并且将非常接近实际值,但缩放结果并不完全可靠。可能会发生这样的情况,即未针对特定实例测量的事件可能在该实例期间出现尖峰或停滞,并且缩放值将具有误导性。
因此,在需要高精度值的情况下,用户应注意被监控的事件获得专用硬件,而不是时分复用。
以下是计数类型测量的示例。 在这里,我们正在测量两种不同类型的矩阵乘法的缓存未命中数。 我们通过利用内存引用的空间局部性将第一种算法设计为比第二种算法更有效,因此预计第一种算法的缓存命中率远低于第二种算法。 我们使用带有 stat 选项的 perf 工具测量了两种乘法算法的缓存命中总数。
4.2. 基于事件的采样
在这种类型的测量中,PMU 计数器被配置为在预设数量的事件后溢出,当发生溢出时,通过捕获指令指针、通用寄存器和 EFLAG 寄存器的数据来记录进程状态信息。 此采样数据可用于分析软件应用程序、查找软件如何利用底层硬件以及许多其他目的。
限制:
- Sampling Delay 计数器溢出与中断发生之间存在延迟。 这与高端处理器中存在的长管道相结合,采样时存储的程序计数器数据可能不是导致计数器溢出的事件。
- 推测性计数 如今,大多数高端处理器都使用分支预测,这会导致指令的推测性执行,如果选择了某个其他分支,这些指令可能无法完成。 但是这些推测执行的指令即使没有完成也可能导致事件并影响事件计数,这是不正确的。
在上一节讨论的示例中,我们看到第二种算法表现不佳。 因此,现在让我们使用 perf record 实用程序找出该程序中花费了大量执行时间的大致位置。 下面是使用 perf 报告解释的 perf 记录输出的快照。
我们可以从图 3a 中看到,99.62% 的样本(使用默认事件周期获取)在 mul4 函数中,该函数是乘以矩阵的函数。 在进一步挖掘中,我们可以从图 3b 中看到,由于许多缓存命中,大量时间用于移动数据。 因此,使用这种技术可以轻松调试软件应用程序中的性能问题。
4.3. 硬件提供其他特性
- 固定功能性能计数器寄存器及相关控制寄存器:
与可配置为测量不同事件的通用计数器不同,有一些计数器只能测量特定事件。
- 全局控制寄存器:
一些架构提供全局控制寄存器,可用于控制所有或一组控制寄存器或计数器。 这减少了修改控制寄存器所需的指令数量,从而简化了编程。
5. Uncore Performance Monitor Units
PMU(performance monitoring units)使用分布式设计,其中计数器在不同 uncore 单元中,不同单元中计数器无法监控其他单元的事件。 不同 uncore 单元如图所示,其中 CBo(C-box)、ARB(arbitration)和 IMC(integrated memory controller)都是 uncore 单元中一部分。

CBox 是负责 LLC 上多个切片一致性的引擎,每个 CBo 提供了 MSRs 来选取 uncore 性能监控事件。MSRs 选取的每个事件与一个计数寄存器相联系。ARB 提供了局部性能计数器和事件,在 ARB 中包含了固定或不可编程的计数器。IMC 包含 5 个模块,其中固定计数器运行监控一些列 DRAM 请求。
5.1. Uncore PMU MSR
在 PMU 中,包含了许多 MSR,并且在Intel 官方手册中,提供了对应寄存器地址1。 每个寄存器都有不同名字和功能,其不同功能实现主要通过修改对应寄存器中 bit 位上的值来实现,因此寄存器的每个位都有对应的 field 名。
5.2. Uncore PMU Events
在 CBo 和 ARB 单元中,不同监控内容有相应的监控事件(Events)。在 Intel 官方手册中对每个事件介绍了对应的事件名,ID,掩码(umask)以及描述。 其中代码写入相应寄存器的 EVT_SEL 位,而掩码则写入寄存器 UMASK 位中。
在 IMC 中,
5.2.1. UBox
UBox 负责 Skylake 平台中系统配置管理者的角色,作为中央控制单元负责以下内容:
- 通过使用 Message Channel 管理读取和写入物理分配的寄存器;
- 中断消息的中间人,从系统接收中断信息随后发送到对应核心上;
- 系统锁管理角色
-
6th Generation Intel® Core™ Processor Family Uncore Performance Monitoring Reference Manual n.d.:20. ↩